消费端线程池模型
Dubbo 消费端线程池模型用法
背景
2.7.5 版本对整个调用链路做了全面的优化,根据压测结果显示,总体 QPS 性能提升将近 30%,同时也减少了调用过程中的内存分配开销。其中一个值得提及的设计点是 2.7.5 引入了 Servicerepository 的概念,在服务注册阶段提前生成 ServiceDescriptor 和 MethodDescriptor,以减少 RPC 调用阶段计算 Service 原信息带来的资源消耗。
示例
消费端线程池模型优化
对 2.7.5 版本之前的 Dubbo 应用,尤其是一些消费端应用,当面临需要消费大量服务且并发数比较大的大流量场景时(典型如网关类场景),经常会出现消费端线程数分配过多的问题,具体问题讨论可参见 Need a limited Threadpool in consumer side #2013
改进后的消费端线程池模型,通过复用业务端被阻塞的线程,很好的解决了这个问题。
老的线程池模型
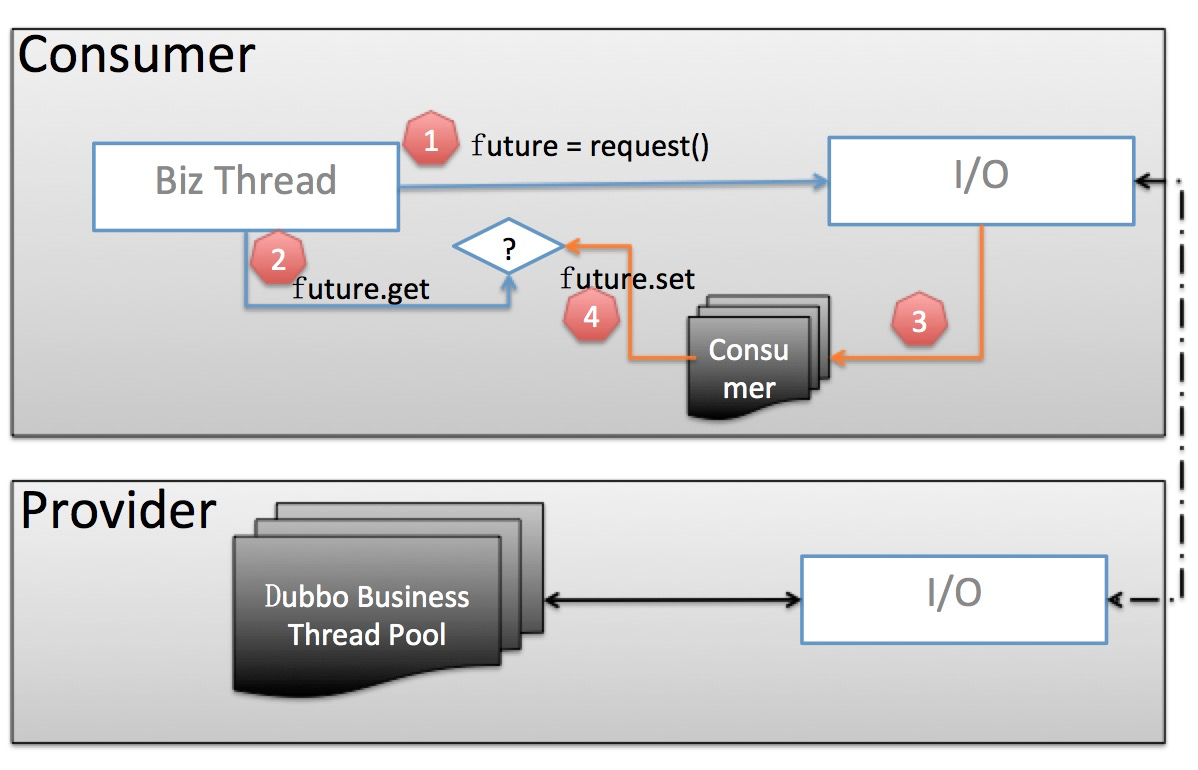
我们重点关注 Consumer 部分:
- 业务线程发出请求,拿到一个 Future 实例。
- 业务线程紧接着调用 future.get 阻塞等待业务结果返回。
- 当业务数据返回后,交由独立的 Consumer 端线程池进行反序列化等处理,并调用 future.set 将反序列化后的业务结果置回。
- 业务线程拿到结果直接返回
2.7.5 版本引入的线程池模型
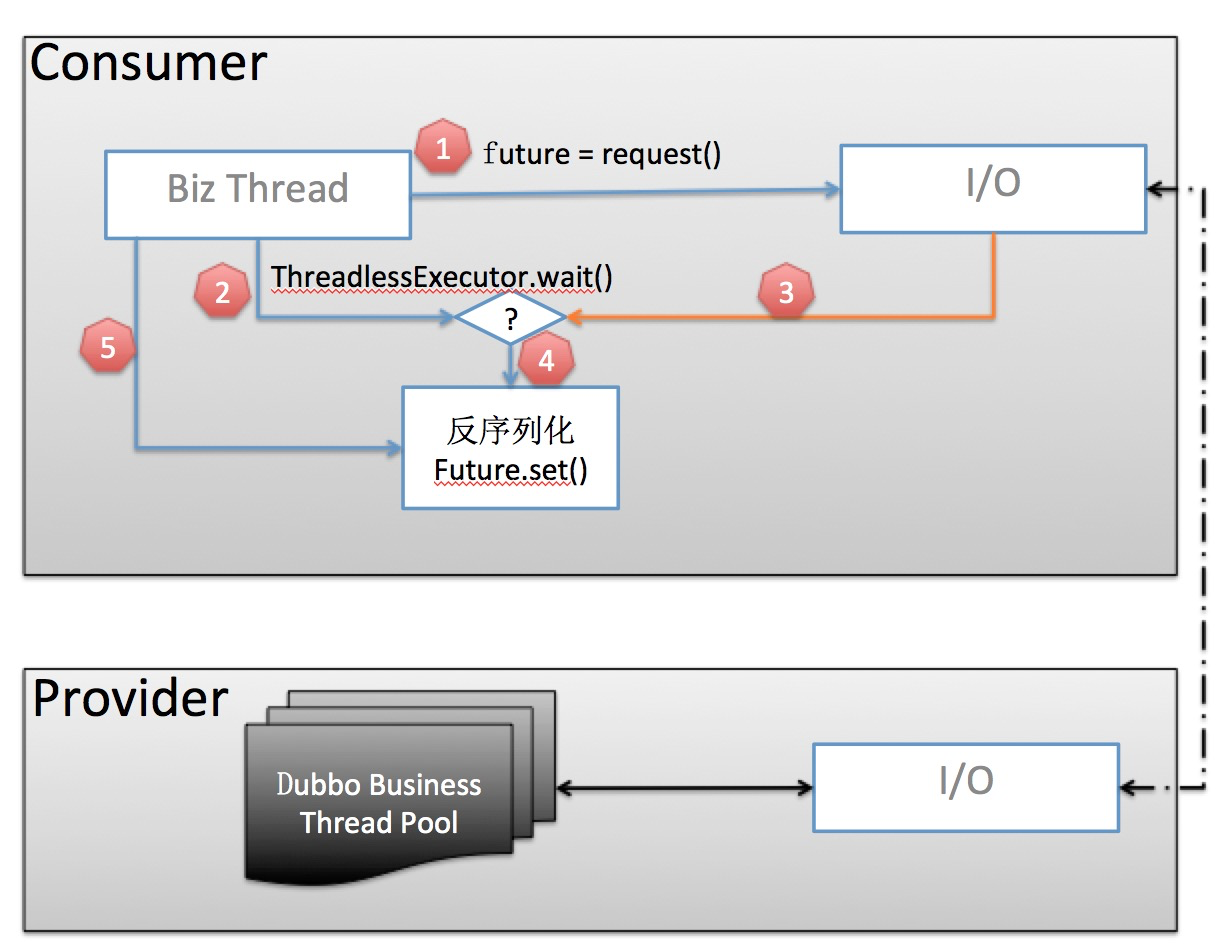
- 业务线程发出请求,拿到一个 Future 实例。
- 在调用 future.get() 之前,先调用 ThreadlessExecutor.wait(),wait 会使业务线程在一个阻塞队列上等待,直到队列中被加入元素。
- 当业务数据返回后,生成一个 Runnable Task 并放入 ThreadlessExecutor 队列
- 业务线程将 Task 取出并在本线程中执行:反序列化业务数据并 set 到 Future。
- 业务线程拿到结果直接返回
这样,相比于老的线程池模型,由业务线程自己负责监测并解析返回结果,免去了额外的消费端线程池开销。
关于性能优化,在接下来的版本中将会持续推进,主要从以下两个方面入手:
- RPC 调用链路。目前能看到的点包括:进一步减少执行链路的内存分配、在保证协议兼容性的前提下提高协议传输效率、提高 Filter、Router 等计算效率。
- 服务治理链路。进一步减少地址推送、服务治理规则推送等造成的内存、cpu 资源消耗。