Seata 微服务架构下的一站式分布式事务解决方案
摘要:本文整理自阿里云分布式事务产品负责人、Seata 开源项目创始人、微服务开源治理负责人季敏的分享。本篇内容主要分为三个部分:
- 一、微服务架构下数据一致性的挑战
- 二、分布式事务Seata的架构演进
- 三、如何基于Seata扩展RPC和数据库
一、微服务架构下数据一致性的挑战

在2019年,我们基于Dubbo Ecosystem Meetup,收集了2000多份关于"在微服务架构,哪些核心问题是开发者最关注的?“的调研问卷。最终分布式事务占比最大,有54%。
但在Seata出现之前,大家都说分布式事务能避就避,因为消息最终一致性去解释了问题。但Seata开源之后,这些问题都迎刃而解。比如无损上下限,到底是说服务的可用性还是其他的。对于我来说,我觉得它最终关注的是数据的问题。因为无论前端的业务怎么去交互,最终都会沉淀到数据。如果业务的数据不一致,前面是什么架构,都意义不太大,所以我认为数据是企业的核心资产。
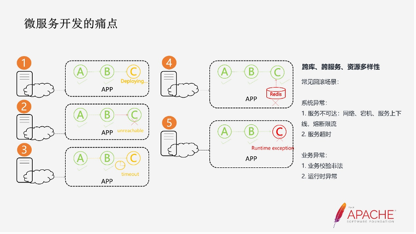
那么到底哪些场景会遇到分布式事务的问题呢?
第一个场景,在拆分成微服务架构之后,不同的服务可能由不同的团队负责上下游的协调联动。比如C服务发布的时候,并不会通知A服务和B服务,这个时候就会遇到上下线带来的数据一致性的问题。
第二个场景,不可靠、不稳定的基础设施,会导致网络或者个别主机的宕机。
第三个场景,timeup是分布式架构里比较难解的状态,因为一旦出现服务调用的timeup,这个服务的业务逻辑到底是执行了,还是没有执行timeup的服务怎么实现数据的密度,都是比较尖锐的问题。
第四个场景,业务里除了会涉及到数据库,还会涉及第三方的组件。比如缓存、Redis,我们的库存会先经过Redis这样的组件,那么如何实现它的一致性也是个问题。
第五个场景,我们在上下游做业务的时候,你传给我一些参数,但这些参数本身可能是非法的。那么我就需要把你的下服务也回关掉,而不是只有我这一个服务去做拒绝。
所以分布式事务的场景主要包括了跨库、跨服务、资源的多样性。异常上主要包括业务异常、系统异常。
那么分布式事务是不是微服务架构独有的问题呢?其实不是,它在单体应用里也有类似的问题,只不过在微服务架构里它的问题更凸显。
在单体架构下存在哪些分布事务的场景呢?比如一个单体应用要去修改多个数据库或者多模块的,整体而言,单体数据库它完成的是ServerSission下边的一个本地事务。只要跨了这个本地事务,其他的都是分布式事务,即使微服务都去修改同一个数据库。这样其实你的数据库的本身也不是能反序列化传递到另外一个服务的,这些问题都会涉及到分布式事物的问题。
整体看起来,分布式事物涉及到了分布式架构和单体架构中非常广泛的应用。
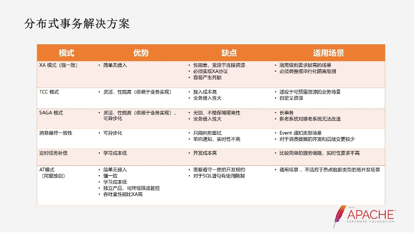
市面上的分布式事务方案有以下六类:
- XA模式,它的问题是吞吐量和性能要差一点,在一致性上是最高水准。
- TCC模式和SAGA模式,可以归结为是一个业务层面的分布式事务,因为他不会拦截数据。比如TCC模式可能有cc接口,至于这个接口怎么回滚,怎么正向的,在框架层面完全不用管。这可能是你里边逻辑本身不是对等的,也不是框架已经参与的,所以更多的是把接口暴露给了业务实现。
- 消息最终一致性,它最大的优点是实现异步化的解耦,结合消息的削峰填补的特点。但它本身存在着一些问题,对消息来说,他更多的是做一个单项的通知。这个通知可能对于一些消息消费来说,即使业务失败了,它也没法去回滚。
比如现金红包的业务,我首先要将红包转到我的账户,然后再从我的账户转到我的银行卡。可能消息消费的时候我这个账户已经注销掉了,那么你的消息消费就会一直处在失败的状态。对于这类问题,不可能再把上游消息的发送给关掉,所以它更多的是单项通知的场景。
- 定时任务补偿,它的学习成本低,但实践成本高。尤其是微服务的链路有多翘的节点,需要业务逻辑写的非常周全。
- AT模式,它综合了一致性性能,主要的特点是简单无侵入,强一致,学习成本低。缺点是需要遵守一定的开发规约,并且它不是对所有的SQL类型都支持,它有一定限制。从业务场景上来说适应的是一个通用的场景,但它并不适应于热点数据类型的高并发场景,比如SKU的库存的部件。因为在这个模式它有一个应用层的分支锁,需要对相同的数据做一个排队的等待。
二、分布式事务Seata的架构演进
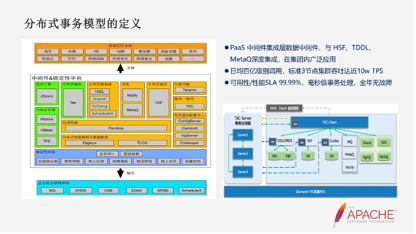
Seata在阿里内部的代号叫TXC,在蚂蚁叫DTX。它起源于集团的五彩石项目,五彩石的项目是当初集团内在做去IOE,从单体架构引进到分布式架构。在分布式架构必然会涉及到很多的中间价,TXC承担的主要的角色做服务一致性的保证。
我们和集团内的三大件都做了深度的集成,包括服务调用框架HSF,也就是对外开源的Dubbo;数据库有分库分表的TDDL组件;异步消息的MetaQ组件。在集团内也有广泛的使用,日均百亿级别调用,标准3节点集群吞吐达近10w TPS。
我们的SLA会分为几个SLA,一个是可用性的SLA服务,另外一个是性能的SLA服务。因为对于分配事物来说,除了要保证一致性,也要保证性能的吞吐量。所以我们规定比如每一次的RT额外的开销不能超过XX。目前能达到毫秒级的事务处理,能保证在稳定性上全年无故障。
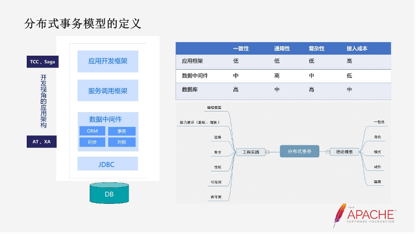
最开始我们在做分布式事务实现的时候,我们也去考虑我们的分布式事务应该是在哪层面去实现?
从应用架构的视角,分为这么几层,一个是最上层的应用开发框架,可能每一套公司都有自己的开发框架,比如像ddt的开发框架或者club的体系等等。再下一层是服务调用框架,类似于Apache Dubbo主要承担,也在国内使用的非常广泛。再下一层是数据中间件,这层主要包括ORM框架、事务、同步、对账。再下一层是跟数据库连接,这一层类似于JDBC、Java去连数据库。
我们去做了一个简单的对比,到底是在哪层实现分布式事务,是在DB层、数据中间件层还是应用框架层?
在应用框架层,它去实现一致性相对来说比较弱,因为你会掺杂很多复杂的、不可控的因素,会把服务调用的因素给牵扯进去。比如服务调用的超时,这就是为什么我们现在有的像TCC模式它会有一些密等、放悬挂那些问题。都是因为融入了RPC的因素,持续的不确性导致的一些问题。
在数据中间件层,它的一致性比应用框架要好一些,它主要的问题是他不是在DB层实现的,所以我是有办法绕过中间件直接去修改DB的,这时候就会存在事物并发时序的问题。最好的一致性是在DB层去实现数据一致性,但这一层数据一致性主要是数据库的厂商,但是也是参差不齐。比如Msever,他在5.7.7版本才把差异完善起来,在之前的版本它对差异回滚一直是有问题的。
但它只能局限在数据库的scope,如果我要去更大的scope,从应用架构层可能要跨服务,跨服务这一层它就管不了,只能管我自己数据库。所以他最终还是需要有一个第三方的去协调跨服务的数据一致性。最终我们把这一层AT差异模式是把它做到了数据库中间件这层,JDBC server这层我们做到了应用开发框架这层。
所以它不仅实现了一整套的集团生产体系,还包括了我们对分布式事务编程模型的定义,运维安全。因为要涉及到数据,会有数据的敏感以及性能和观测高可用等等。
在理论模型上我们当时还是比较匮乏的,我们做了一些对差异以及Spring事物模型的延展。我们延展了已有的模型,而不是新造一条。这于开发者来说,学习成本会更低。
此外,我们还做了一些定义,包括怎么定义一致性,是定义多节点的一致性,还是业务应用架构数据的一致性,以及这套架构里的角色模型设计的事物动作和隔离。
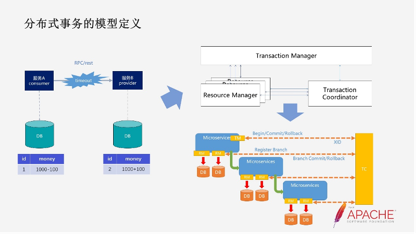
什么是分布式事务的模型定义?举个例子,我去做银行转账的时候,我给你转100块钱,恰好这个时候出现了网络超时,那么这100块钱到底有没有扣。如果不确定就可能出现资损的问题,甚至可能影响企业的商誉。
我们都在谈分布式架构,但从整个应用的视角,并不是所有东西都是分布式的。比如我们从一个应用的架构的层面去看数据库,包括今天称之为分布数据库。从整个应用层面,它我们看它是一个集成式的数据的存储。它的内部实现可能是分布式的,包括分布式的链路数据。
因为在分布式的应用架构里,每个业务的节点都只掌握了部分的信息。如果做一些问题的排查,必然需要一个集成式的东西。对于分布式事务它的核心工作是做分布式协调,所以他要掌握全局的信息。
这就是为什么我们有了Transaction Coordinator。对他来说,他要有一个上帝视角,充当第三方的协调器。而真正做事的是Resource Manager,你可以认为它是数据库的灵魂,我们需要把它作为Pro。
真正随着业务应用去做事务的动作是Transaction Manager,它会随着业务的执行链路进行,到底直接事务的边界是怎么样的,以及分布式事务的动作是怎么样的。
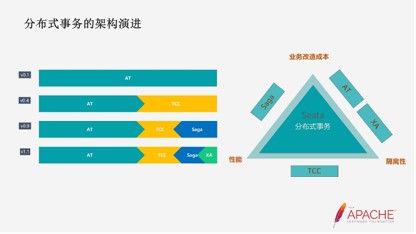
2019年1月Seata开始开源了,我们主打的特点特色是AT 模式,因为是组装,我们从0.1版本就把AT模式给开源出去了。0.4版本我们纳入了TCC的模式,因为AT模式它需要适配不同的数据库。而在现有阶段我们不能满足对所有数据库的支持以及缓存资源,这就需要应用TCC模式去做补充。你可以用TCC模式做一些我们没实现的数据库以及缓存的结构。
在0.9版本,我们纳入Saga的事务模式,它主要解决长事务方解决方案。比如一个事务非常长,且还有微服务的编排工作。在1.1版本,我们纳入了XA的事务模式,因为有的客户已经应用了Seata的AT模式,但他还有一些老的特别事务。他希望应用Seata统一的一套解决方案,解决不同业务常用的分支事务,所以我们把XA的事务模式也纳入进来了。
最终从整个架构上来说,我们是打造了一站式的分布式事务的解决方案。针对不同的业务场景,Seata都能做事务。如上图所示,目前市面上没有一只分布事务的模式,能解决不同业务场景的问题。主要强调几个问题,分布式事务可能有同步的分布式事物,有异步的分布式事务,以及对分布式事务的一致性的要求也不高。有强一致性,最终一致性,弱一致性。
另外,对于事物执行时间的长短也有要求。比如有长事务、短事务以及性能吞吐量等等。所以我们纳入了现在的四种事务模式,它们从改造成本、性能隔离性上各有所长,这里就不展开介绍了。
三、如何基于Seata扩展RPC和数据库

首先看一下Seata开源社区这几年的发展。目前Seata已经具备了AT、TCC、Saga、XA四种事务模式,而且对于市面上主流的关系数据库,RPC框架做了广泛的支持,同时被许多第三方社区做了主动和被动集成。已经和三十多个社区做了集成,这些集成都放在我们的扩展机制里边。
目前多语言体系也做起来了,除了最开始的Java,Go语言支持的也非常成熟,欢迎大家去使用我们的Go版本,给我们提更多宝贵的建议。另外,我们还建建设了多语言版本,包括PHP、Python等等。
目前 Seata 开源产品已被上千家企业在业务系统中应用,金融企业纷纷试点。我们都知道金融类的业务对分布式事务是强需求,而且它的业务场景非常严苛。像中信银行、光大银行、农行我们也做了一些社区上的合作,改造一些他们的核心账务系统,用Seata保证他们账务体系的数据一致性。
目前Seata社区的Star数已经到达了24k,contributor有300+。并且Seata社区是非常开放的,现在整个Seata的框架代码有70%来自创始团队之外的外部贡献者,所以欢迎大家积极的参与到我们Seata社区里。

接下来介绍一些Seata比较典型的企业案例。
第一个案例,中航信航旅纵横项目。中航信是Seata 最早的天使用户,用的是Seata 0.2版本。如果大家出差比较频繁,应该会用到它们的APP,航旅纵横。它解决机票和优惠券业务的数据一致性问题。虽然在早期的版本中陪我们踩了不少坑,但最终还是应用起来。
第二个案例,滴滴出行二轮车事业部。它在Seata 0.6.1版本就将 Seata 引入到了二轮车事业部的各个业务中,包括市面上大家看到青桔单车,还有他们内部的资产管理。
第三个案例,美团基础架构。美团基础架构团队基于开源 Seata 项目封装了内部分布式事务 Swan 项目,作为美团内部各业务解决分布式事务问题的组件。
第四个案例,盒马小镇。盒马小镇游戏互动中通过 Seata 控制偷花的流程,开发周期从20天下降至5天,大幅度减少了开发的成本。
综上可以发现分布式事务的两个价值。
- 业务的正确性,因为只有数据一致了谈架构才有意义。
- Seata大幅度提高了开发迭代的效率。
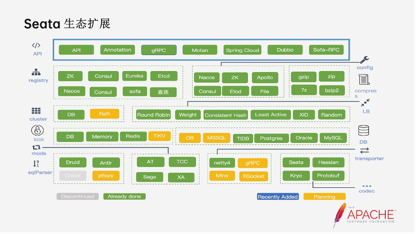
上图是Seata生态的扩展点。最上层我们定义了API这一层,中间这一层包括注册、配置中心等等,下边是群的模式,包括基于关系数据库DB的,Redis的以及现在2.x里正在推广的rough模式,负载均衡也有各种模式,以及对于分布式锁扩展也是基于各种各样的模式。目前我们对于关系型数据库也支持的挺多的。

我们在做Seata机制的时候参考了Dubbo的机制,对我们的学习成长以及社区的成长还是非常有帮助意义的。我们把扩展点充分发挥到了极致,分为server侧的扩展点以及客户端的扩展点。客户端扩展点大概有30+个,server侧的扩展点包括锁的扩展、存储的扩展以及事务模式的处理。
从今天来看如果你去支持数据库、国产达梦、人大金仓,成本都比较低。只要按照我们的文档,按照API的扩展点去做简单的实践,就能把整个流程跑起来。另外,我们server不同的锁的存储,事务筛选的存储都是可以扩展的。这里我们也是借鉴了Dubbo去做了一些对开发者非常友好的扩展,让开发者更容易的扩展市面上的RPC框架以及数据库。
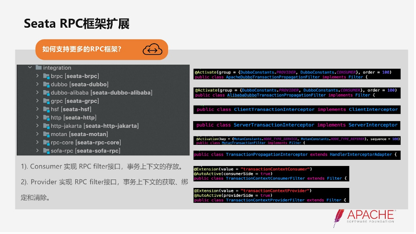
目前我们支持了11中RPC框架,Dubbo是我们核心要支持的。我们类似于Dubbo,基于一般RPC都有fell或者ins。我们核心要做的是把Seata事物上下文通过服务调用链路给传递下去。并且把事物链路还原到服务里边去做事物的绑定、解除、清除等等,这个核心我们扩展起来还是比较容易的。
核心的话右边我们实现了一些接口,目前我们对Dubbo生态,包括老的阿里巴巴Dubbo以及Apache我们都做了充分的支持。欢迎大家在Dubbo的生态去适应一下Seata分布式事物去体验一下。
目前Seata数据库支持MySQL、OceanBase、Oracle等等数据库,其中有一些PR还没有合并,比如达梦、IBMDB2。就像我刚才说的,我们只要基于当前的扩展点,我们就能做充分的扩展。
最近我们也是做仓库的编程之下,也是让我们眼前的同学感觉一下,它也做了一些PolarDB的支持,后边我们会对数据库的生态top 20完整的支持起来。